As I demonstrated before, the same malformed file system structures can cause overflows/over-reads in independently developed software.
Here is a recent example: a buffer overflow vulnerability found in 7-Zip — CVE-2023-52168. This vulnerability is similar to one previously discovered by me in the ntfsck tool (from the NTFS-3G driver) — CVE-2021-46790.
And even more: a buffer over-read vulnerability in 7-Zip — CVE-2023-52169. It shares the same mechanics as a kernel memory disclosure vulnerability in the Linux ntfs3 driver — CVE-2023-45896.
Two buffer overflow vulnerabilities mentioned above are caused by the so-called update sequence array.
This is an array of two-byte elements which is used in the NTFS file system to reliably detect torn (partial) writes of multiple sectors to traditional storage devices (like hard disk drives).
Let’s consider the following scenario: we have a data chunk (e.g., a file system structure) that spans across two sectors. We need to update the whole structure (i.e., two adjacent sectors) at once.
In the HDD world, in general, we can atomically overwrite one sector*. But we have two of them… If there is a system crash or a power loss event before we write to the second sector (let’s call it “sector #2”), but after we wrote to the first one (“sector #1”), we would end up with inconsistent data (sector #1 contains “new” data, while sector #2 contains “old” data).
* — keep in mind that, outside of the HDD world, byte-addressable storage devices break this assumption.
If there are no additional measures to detect such inconsistencies, software parsing that data chuck would use “old” (and no longer valid) data from sector #2 while thinking it is “new” (like in sector #1, which is the only sector updated before the failure).
Today, developers use checksums to validate on-disk data (we can calculate a checksum over bytes from both sectors and store it somewhere, in one of those sectors). But the NTFS file system was designed to use another approach:
- the NTFS driver creates a two-byte (16-bit) placeholder value;
- the NTFS driver copies the last two bytes from sector #1 and from sector #2 into sector #1, into the update sequence array specifically (this happens in memory);
- the NTFS driver replaces the last two bytes of those two sectors with that placeholder value and also stores the placeholder value into the update sequence array (again, in memory);
- the NTFS driver writes both sectors to the underlying drive.
Here is an example (with 4 sectors used by one structure):

(Source.)
So, when reading from a drive, we can easily detect torn writes* by comparing the last two bytes of each sector (within a single multi-sector structure) against a placeholder value, which is recorded in the first sector (of that multi-sector structure). (It is assumed that a placeholder value is different on every write of that multi-sector structure.)
* — and even subsector torn writes, because the placeholder value is stored in the beginning of the first sector as well as in its last two bytes. If there was a failure when writing to the sector (i.e., a partial write), these values are going to be different.
If the last two bytes of a current sector match the placeholder value, this sector is up-to-date (and we can restore the original values of the last two bytes of that sector, since they were stored in the update sequence array, which is in sector #1). Otherwise, the sector wasn’t updated for some reason (there was a torn write).
The update sequence array is stored in sector #1 and it consists of the following elements:
- a placeholder value (two bytes);
- original values to be restored (two bytes each).
The update sequence array length (as a number of two-byte elements) is also stored in sector #1.
For a file system structure occupying 1024 bytes (i.e., two 512-byte sectors, like a file record segment in the NTFS file system), the only valid size of the update sequence array is 3 elements (one placeholder value, two original values). However, we can craft a file system image that contains more elements in the update sequence array than required.
Most NTFS drivers/parsers will reject such an invalid update sequence array, but if there are no proper boundary checks, it would trigger an out-of-bounds write of two bytes, at the following offsets: 512*i-2 (in the 1024-byte case, when the allocated buffer size is 1024 bytes, i is 3, 4, 5 and so on).
This happened to the ntfsck tool (report). And now, to the 7-Zip archiver!
Before 7-Zip 24.01 beta, it was possible to craft a file system image that would trigger the overflow.
The vulnerable code in the NTFS handler was:
In the CMftRec::Parse() function (some comments starting with “//” are mine):
{
UInt32 usaOffset;
UInt32 numUsaItems;
G16(p + 0x04, usaOffset); // 'p' here is 'ByteBuf' in another function below.
G16(p + 0x06, numUsaItems); // Get the update sequence array length from a disk.
/* NTFS stores (usn) to 2 last bytes in each sector (before writing record to disk).
Original values of these two bytes are stored in table.
So we restore original data from table */
if ((usaOffset & 1) != 0
|| usaOffset + numUsaItems * 2 > ((UInt32)1 << sectorSizeLog) - 2
|| numUsaItems == 0
|| numUsaItems - 1 != numSectors) // 'numSectors' here is 'numSectorsInRec' in another function below.
return false;
[...]
UInt16 usn = Get16(p + usaOffset); // Get the placeholder value that should be stored in the last two bytes of the sector.
// PRF(printf("\nusn = %d", usn));
for (UInt32 i = 1; i < numUsaItems; i++) // No proper boundary checks here! 'numUsaItems' is attacker-controlled!
{
void *pp = p + (i << sectorSizeLog) - 2;
if (Get16(pp) != usn) // Check if the placeholder value matches the last two bytes of the current sector.
return false;
SetUi16(pp, Get16(p + usaOffset + i * 2)); // If so, restore the last two bytes of the current sector.
}
}In the CDatabase::Open() function:
UInt32 blockSize = 1 << 12; // 4096 bytes!
ByteBuf.Alloc(blockSize); // Allocate the buffer containing 4096 bytes.
RINOK(ReadStream_FALSE(InStream, ByteBuf, blockSize));
{
UInt32 allocSize = Get32(ByteBuf + 0x1C); // Read the allocated structure size from a disk.
int t = GetLog(allocSize);
if (t < (int)Header.SectorSizeLog)
return S_FALSE;
RecSizeLog = t;
if (RecSizeLog > 15)
return S_FALSE;
}
numSectorsInRec = 1 << (RecSizeLog - Header.SectorSizeLog);
if (!mftRec.Parse(ByteBuf, Header.SectorSizeLog, numSectorsInRec, 0, NULL)) // 'numSectorsInRec' here is the same as 'numSectors' in the function above.So, in general, in order to validate the number of the update sequence array elements, the code quoted above uses data from a disk (or a file system image) solely. Which is attacker-controlled, of course.
It is possible to craft a file system image in a way that: ‘allocSize‘ is larger than 4096 bytes (e.g., 32768 bytes) and ‘numUsaItems – 1 != numSectors‘ is false, while the allocated buffer size (‘ByteBuf‘) is always 4096 bytes. When restoring the last two bytes of each sector, this allows out-of-bounds writes, beyond the boundary of the 4096-byte buffer.
Such an overflow is very hard to exploit, but who knows…
Timeline (for the 7-Zip archiver)
- 2023-08-18: the vulnerability was reported by me to Igor Pavlov.
- 2024-01-31: a fixed version (24.01 beta) is available.
And two buffer over-read vulnerabilities occur when parsing a file name from the NTFS file system.
In the NTFS file system, file names are stored as wide (UTF-16LE) strings in the $FILE_NAME structure, which has the following layout:

(Source.)
The idea is to modify the $FILE_NAME attribute, so its “Filename length in characters” value becomes larger than a corresponding memory allocation containing the attribute. If there are no proper boundary checks, arbitrary data would appear as a part of a file name string.
In the NTFS handler (7-Zip), there was a typo in the file name length check:
bool CFileNameAttr::Parse(const Byte *p, unsigned size)
{
if (size < 0x42)
return false;
G64(p + 0x00, ParentDirRef.Val);
// G64(p + 0x08, CTime);
// G64(p + 0x10, MTime);
// G64(p + 0x18, ThisRecMTime);
// G64(p + 0x20, ATime);
// G64(p + 0x28, AllocatedSize);
// G64(p + 0x30, DataSize);
G32(p + 0x38, Attrib);
// G16(p + 0x3C, PackedEaSize);
NameType = p[0x41];
unsigned len = p[0x40];
if (0x42 + len > size) // Should be: 0x42 + len * 2 > size
return false;
if (len != 0)
GetString(p + 0x42, len, Name); // This extracts a wide character string (UTF-16LE) from 'p + 0x42'.
return true;
}The check incorrectly treats the “Filename length in [UTF-16LE] characters” field as “Filename length in bytes”. So, it’s possible to include data beyond the $FILE_NAME attribute in memory as a part of a file name string (if ‘0x42 + len > size‘ is false, but ‘GetString(p + 0x42, len, Name)‘ extracts data up to ‘p + 0x42 + len * 2‘).
In the Linux ntfs3 driver, there is no check at all:
if (ino == MFT_REC_ROOT)
return 0;
/* Skip meta files. Unless option to show metafiles is set. */
if (!sbi->options->showmeta && ntfs_is_meta_file(sbi, ino))
return 0;
if (sbi->options->nohidden && (fname->dup.fa & FILE_ATTRIBUTE_HIDDEN))
return 0;
name_len = ntfs_utf16_to_nls(sbi, fname->name, fname->name_len, name,
PATH_MAX);
if (name_len <= 0) {
ntfs_warn(sbi->sb, "failed to convert name for inode %lx.",
ino);
return 0;
}In both cases (ntfs3 and 7-Zip), a missing check exposes some memory beyond the intended buffer (exposed as a part of a file name string).
In the ntfs3 case, this exposes some amount of kernel memory to userspace programs. In my tests, an unprivileged user could leak addresses from the “/proc/kallsyms” file by attaching a USB drive containing a crafted file system image, mounting it (in many Linux distributions, unprivileged users are allowed to mount file systems on removable drives), and listing its contents.
In the 7-Zip case, things are more complicated: there is no obvious impact of exposing bytes from memory allocations of an application launched by the same user. However, the 7-Zip library can be used by online services to parse archives uploaded by untrusted users. If the same application instance is used to parse archives uploaded by multiple users, this could expose secrets from one archive to a different user. (Update, 2024-07-03: and there was one online service working this way, affected by the vulnerability.)
Timeline (for the ntfs3 driver)
- 2023-08-13: the vulnerability was reported by me the Linux kernel security team.
- 2023-08-13: Greg KH and Linus Torvalds told me that this is not a security issue.
According to Greg KH:
The filesystem developers say that “manually corrupted filesystem images are not a security problem”. But it is a bug, so let’s fix it and get it merged please. That’s the best way, and isn’t worth haggling over “was this specific bugfix a security fix”.
Remember, in the kernel “a bug is a bug is a bug” 🙂
As a side note: unprivileged users can mount crafted file system images on removable drives, and exposing chunks of kernel memory to such users is a vulnerability. And even remote attack vectors are possible when a file system image is mounted from a network-based source (like NAS or SAN)… Are your VMware ESXi datastores local?
For the 7-Zip archiver, the timeline is the same as described above, in the overflow case (two vulnerabilities were reported and fixed together).
Update (2024-07-03):
Igor Pavlov, the author of 7-Zip, refused to provide an advisory or any related change log entries.
If we open it now [my note: “now” is 272 days from the vulnerability report, 106 days from the released fix], it will increase the risks for possible attacks as I suppose.
Here is a screenshot of my report. The patched code is… For the overflow:

The “MftRecordSizeLog” variable is properly validated:
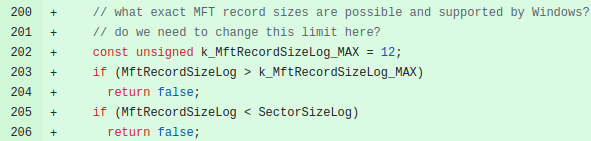
And, for the over-read:

Also, note that CVE IDs assigned to the new vulnerabilities described in this post are still marked as reserved.
MITRE didn’t reply to my publication request.
Update (2024-08-28): CVE-2023-45896 is now public, but marked as disputed (and fixed).
If unprivileged users read bytes from kernel memory, this is a vulnerability. But if they do so using a malicious file system image, it’s not.
Two other CVE IDs (for 7-Zip) became public earlier (in July).
Update (2024-09-04): CVE-2023-45896 wasn’t fixed in the Linux kernel version 6.5.11, contrary to the CVE ID description.
** DISPUTED ** ntfs3 in the Linux kernel before 6.5.11 allows a physically proximate attacker to read kernel memory by mounting a filesystem (e.g., if a Linux distribution is configured to allow unprivileged mounts of removable media) and then leveraging local access to trigger an out-of-bounds read. A length value can be larger than the amount of memory allocated. […]
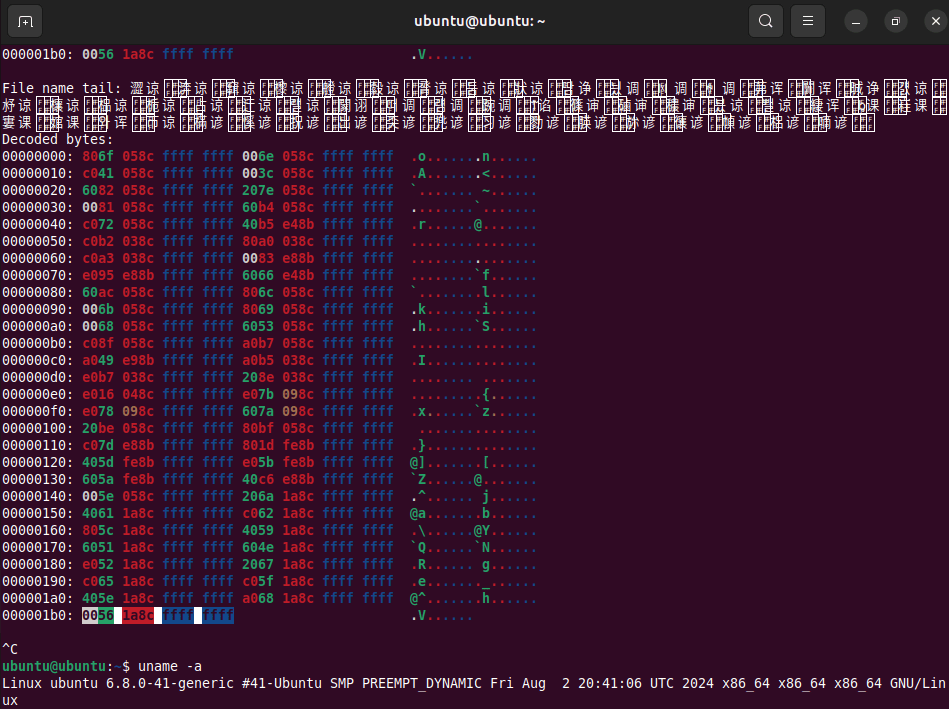
I was able to reproduce the issue using the Linux kernel version 6.8.0 (as shipped in Ubuntu 24.04.1).
It seems that MITRE misrecognized sanity checks implemented for the name field of the attribute header, because the actual out-of-bounds read reported by me was in the name field of the $FILE_NAME structure, which is placed after the unnamed attribute header (see: this and this).
Again: the vulnerability wasn’t fixed in the Linux kernel version 6.5.11!
Here are the screenshots of my proof-of-concept code running on a “fixed” version (this is exactly the same code that was originally sent to the Linux kernel security team):


5 thoughts on “Vulnerabilities in 7-Zip and ntfs3”