Recent releases of Windows 10 (available since the Insider Preview build 10525) include the memory compression feature, which is capable of reducing the memory usage by compressing some memory pages and storing them in the so-called compression store (these pages are decompressed back to their original form when they are needed).
According to Windows Internals, Part 1 (7th edition), the Xpress algorithm is used to compress memory pages, but no specific details were provided about that algorithm. According to Microsoft, the Xpress algorithm has three variants:
- LZNT1,
- plain LZ77,
- LZ77+Huffman.
According to the kernel code, the memory compression feature can utilize the following variants of the Xpress algorithm:
- COMPRESSION_FORMAT_XPRESS (plain LZ77),
- COMPRESSION_FORMAT_XPRESS_HUFF (LZ77+Huffman).
Currently, the kernel is using the plain LZ77 variant.
I doubt that Microsoft will ever switch to the LZ77+Huffman variant, because it is slower and data compressed using this algorithm should be stored along with the Huffman table, which is always 256 bytes in length (thus, a compressed page cannot be smaller than this). But who knows?
In the compression store, each compressed memory page is stored in one or more chunks, each chunk is 16 bytes in length (a compressed memory page can span many chunks, thus compressed data for a single memory page is always aligned to 16 bytes). Compressed memory pages are managed with a B+Tree: it is used to store the location (offset) and the compressed size for every compressed memory page (so the kernel knows where to find compressed data for a requested memory page).
Finally, what does it mean?
- Some memory pages in Windows 10 installations can be compressed.
- Compressed memory pages are managed in a way that is not readily available for memory forensics frameworks and tools.
Example
Let’s estimate the number of memory pages stored in the compressed form. I will use the 2018 Lone Wolf Scenario: this scenario includes a memory dump and a disk image containing a page file (“pagefile.sys”) from a Windows 10 “Redstone 3” installation (which was used on a computer with 16 GB of RAM).
Since I don’t know an easy way to count allocated memory pages stored in the compressed form, I will look for bytes that look like a compressed memory page containing a specific signature (as its first bytes). Such results will also include free memory pages, this is useful for forensics.
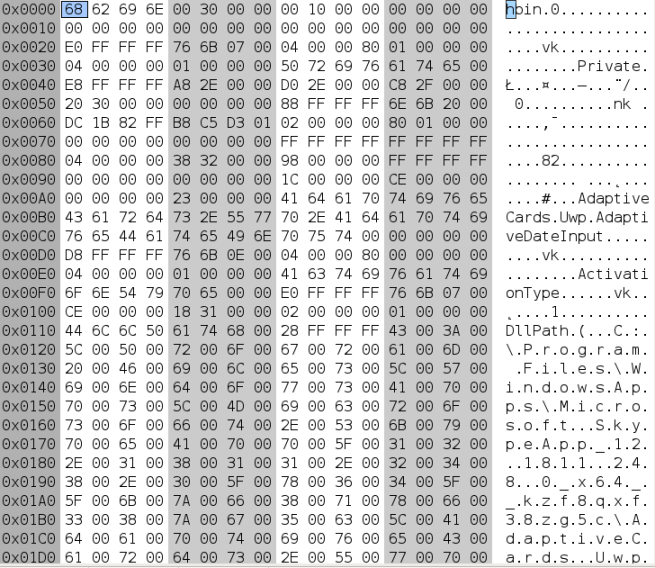
The method is simple: the plain LZ77 compression algorithm is unable to compress unique bytes in the beginning of an input buffer, these bytes are stored in the literal form after a 32-bit integer (which is used to store compression flags); in order to locate compressed memory pages starting with a known signature, walk through all 4096-byte memory pages using 16-byte increments. If data at an offset being probed contains a 32-bit integer followed by a given signature, read at most 4096 bytes (this is the size of a memory page) and try to decompress them.
Since the exact size of compressed data is unknown (unless the method can interpret metadata structures used to manage compressed memory pages), the decompression function will write garbage to the end of the decompressed buffer, which can be easily detected and discarded (in particular, a valid decompressed buffer should be 4096 bytes in length, thus any extra bytes can be thrown away). Additionally, it could be possible to validate the decompressed buffer (by checking whether it contains expected data or not), thus the method won’t take invalid data into account.
In this test, I will look for compressed hive bins (these are allocation units used to store registry structures), because registry data is subject to memory compression. Each hive bin starts with the “hbin” signature (4 bytes) and the internal structure of a decompressed hive bin can be validated, so invalid data won’t be counted as a valid compressed memory page containing a hive bin. Additionally, hive bins that are stored in the literal (not compressed) form will be counted separately.
The results are the following:
- memory dump: 45125 not compressed hive bins, 922 compressed hive bins (2% of hive bins are in the compressed form);
- page file: 1044 not compressed hive bins, 4728 compressed hive bins (82% of hive bins are in the compressed form).
An example of a compressed hive bin found in the page file is shown below:


One thought on “Memory compression and forensics”