Previously, I demonstrated that a live forensic distribution can automatically mount file systems on suspect (internal) drives during the boot process. Also, a proof-of-concept scenario was developed to show that this issue can lead to automatic execution of malicious code (i.e., a program located on a suspect drive gets executed by a live forensic distribution during the boot).
Today, let’s talk about other implications of that issue.
It was demonstrated that, in order to locate a boot drive, a live forensic distribution can mount a file system on an internal drive using the “ro,noatime” options.
The “ro” option is used to mount a file system read-only and the “noatime” option is used to explicitly disable access time updates (this is redundant when the “ro” option is given).
Are these options forensically sound? No.
The “ro” option is used to keep user data read-only, not file system metadata or other structures like a journal. The most impressive example is the Ext4 file system in the dirty (not properly unmounted; e.g., after pulling the plug) state: when such a file system is mounted with the “ro” option, its journal is replayed to bring the file system data to the consistent state.
The following set of commands can be used to reproduce such behavior (root privileges required):
dd if=/dev/zero of=ext4.raw bs=1024 count=10240 status=none # Create an empty image. mkfs.ext4 ext4.raw # Format this image to the Ext4 file system. losetup /dev/loop0 ext4.raw # Create a loop device for the image. mount -o rw /dev/loop0 /mnt/tmp/ # Mount the loop device in the read-write mode. cp ext4.raw ext4-dirty.raw # Copy the mounted file system to a new image. umount /mnt/tmp/ # Unmount the original image. losetup -d /dev/loop0 # And free the corresponding loop device. losetup /dev/loop0 ext4-dirty.raw # Create a loop device for the new image. md5sum ext4-dirty.raw # Calculate a hash value for the new image before mounting. mount -o ro /dev/loop0 /mnt/tmp/ # Mount the file system in the read-only mode. umount /mnt/tmp/ # Unmount the file system. md5sum ext4-dirty.raw # Calculate a hash value for the new image again. It should be different! losetup -d /dev/loop0 # Free the loop device.
After the commands listed above have been executed, the following messages can be observed in the kernel log:
EXT4-fs (loop0): INFO: recovery required on readonly filesystem EXT4-fs (loop0): write access will be enabled during recovery EXT4-fs (loop0): recovery complete EXT4-fs (loop0): mounted filesystem with ordered data mode. Opts: (null)
Also, hash values calculated for the “ext4-dirty.raw” image before and after the mount command won’t match.
As you can see, the “ro” mount option doesn’t guarantee the read-only operation. So, booting an Ubuntu-based live distribution may result in the recovery of file systems residing on internal drives of a computer.
To confirm this, let’s try to boot an Ubuntu 18.04 Desktop image with a dirty Ext4 file system image attached as the first partition of the first HDD (sda1). The live distribution will be launched from a CD.
After the boot, the following messages can be observed in the kernel log:

So, yes, booting a live distribution can alter the data on an internal drive. Now, let’s evaluate a live forensic distribution.
Let’s try PALADIN 6.09 (https://sumuri.com/; this version was validated by NIST, see this PDF report). The test setup is the same as in the case described above. The “forensics mode” was selected during the boot.
The following kernel messages were seen after the live distribution has finished the boot:

The hash value for the drive calculated after the boot doesn’t match the hash value calculated before the boot.
Now, let’s try PALADIN 7.04 (https://sumuri.com/). The test setup is the same. The “forensics mode” was selected during the boot.
The following kernel messages were seen after the live distribution has finished the boot:

As you can see, initramfs scripts failed to recover the Ext4 file system. The hash value for the drive calculated after the boot is the same as before the boot. Thus, the drive is intact.
This is because PALADIN 7.04 includes a simple software write blocker, which marks block devices as read-only and blocks (at the kernel level) write requests going to block devices with this mark set.
It was discovered that the distribution will reset a block device back to the read-write mode if a corresponding drive presents itself as writable (e.g., the WP bit isn’t set in the SCSI MODE SENSE data) and this drive reports an unreadable (bad) sector to a host (as a reply to a read command). The reason for this is that a kernel is revalidating a faulty drive when an I/O error occurs; during the revalidation, all block devices created for such a drive receive the write protection flag as reported by the firmware of that drive.
Depending on the location of an unreadable (bad) sector, the write protection can be disabled for a drive after the boot, when this drive is being aggressively read (e.g., during the acquisition process, or during the verification process, or when a user tries to read a file containing an unreadable sector during the triage process), or during the boot (when initramfs scripts search for a boot drive).
If the write protection is disabled after the boot, then mounting a file system “read-only” using PALADIN Toolbox may result in the Ext4 file system recovery in the same way as described above (because PALADIN Toolbox doesn’t re-enable the write protection flag and the file system is mounted using the “ro” option).
If the write protection is disabled during the boot, then the Ext4 file system recovery may occur just like in the version 6.09 of PALADIN. The following kernel messages can be observed when the write protection is disabled during the boot:
[ 9.088138] ata2.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x0
[ 9.089361] ata2.00: BMDMA stat 0x25
[ 9.090573] ata2.00: failed command: READ DMA
[ 9.091777] ata2.00: cmd c8/00:08:00:08:00/00:00:00:00:00/e0 tag 0 dma 4096 in
res 53/40:01:00:08:00/00:00:00:00:00/e0 Emask 0x8 (media error)
[ 9.094242] ata2.00: status: { DRDY SENSE ERR }
[ 9.095465] ata2.00: error: { UNC }
[ 9.157404] ata2.00: configured for UDMA/133
[ 9.157411] Buffer I/O error on dev sda, logical block 256, async page read
[ 9.158661] ata2: EH complete
[ 9.163365] EXT4-fs (sda2): INFO: recovery required on readonly filesystem
[ 9.163366] EXT4-fs (sda2): write access will be enabled during recovery
[ 9.163841] EXT4-fs (sda2): recovery complete
[ 9.164226] EXT4-fs (sda2): mounted filesystem with ordered data mode. Opts: (null)
Some live forensic distributions implement different approaches to protect the integrity of evidence drives.
For example, evaluation versions of SMART Linux were using the “ro,loop” options to mount file systems after the boot (if requested by a user). This approach doesn’t protect file systems against write requests sent during the boot because initramfs scripts are mounting file systems on internal drives using the “ro,noatime” options. Also, the “ro,loop” options don’t protect file systems which are natively stored on two or more block devices (e.g., an Ext4 file system with an external journal); the reason is that a read-only loop device created by the mount command protects a single block device only (the one specified for the mount command); other block devices, which can be picked by a file system driver using file system metadata, aren’t protected against write requests with loop devices.
Another example is a forensic distribution marking block devices as read-only using the blockdev command (with the “–setro” option, note that there are two hyphens, but the WordPress engine replaced them with a single dash) or the hdparm command (with the “-r1” option). Without a kernel patch, a kernel may write to block devices marked as read-only (e.g., because of a bug in a file system driver; such bugs are a known issue).
Other distributions
Live forensic distribution based on Debian can alter the data on suspect drives in similar situations. However, because the probing scheme is different (this was described in that post), the issue can be reproduced in more specific configurations.
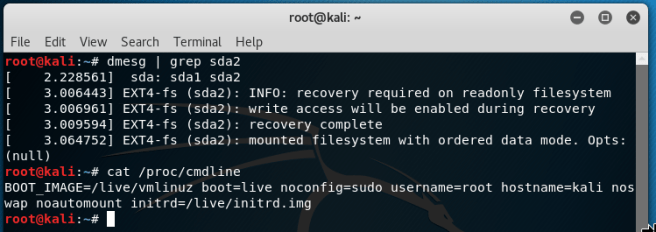
For example, Kali 2018.2 (https://www.kali.org/) automatically recovers, during the boot in the forensic mode, a dirty Ext4 file system residing on an internal drive if one of the following conditions is met:
- the live distribution starts from an internal drive;
- the live distribution starts from a drive in a USB enclosure;
- the live distribution starts from a “non-removable” USB Flash stick (according to the RMB bit in the SCSI INQUIRY data);
- in other cases: if a boot drive isn’t recognized by a live system or it’s recognized after a significant delay (e.g., due to a hardware issue).
The first three conditions refer to the situation with a “non-removable” boot drive. A screenshot to demonstrate this behavior is below:
Swap partitions, software RAID and LVM volumes
Besides mounting a file system on a suspect drive, live forensic distributions can activate swap partitions, software RAID and LVM volumes on that drive (and on any other suspect drive attached to a computer). These actions can violate the integrity of digital evidence too.
For example, activating a swap partition on a suspect drive may result in data being written to this partition (when memory pages used by a live distribution are swapped out from RAM).
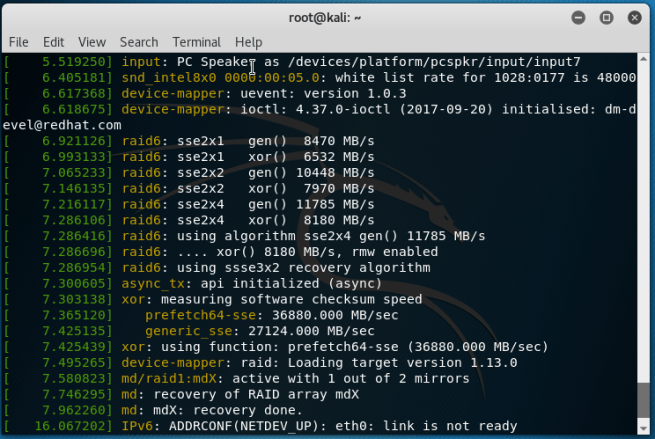
When software RAID and LVM volumes are activated, various implicit changes can be made to underlying storage devices. On a screenshot below, Kali 2018.2 is recovering (automatically, during the boot in the forensic mode) a RAID1-like (mirrored) LVM volume stored on two suspect drives (physical volumes on these two drives weren’t synchronized and the live distribution writes “newer” volume data to the drive with “older” volume data to keep both drives in sync).
For more information about the mount process and its forensic implications, see the Linux write blocker project (and some test cases, including the LVM setup: here and here).
The NTFS $LogFile issue
Let’s start with a screenshot taken after the boot of PALADIN 6.09 on a computer with Windows 7 installed (after pulling the plug from this computer):

As you can see, the NTFS $LogFile was wiped with the 0xFF pattern!
What happened?
Let’s take a look at the NTFS-3G source code. We have a strange message (“The disk contains an unclean file system…“), so let’s find a function responsible for printing this message. Here it is:
/**
* ntfs_is_logfile_clean - check in the journal if the volume is clean
* @log_na: ntfs attribute of loaded journal $LogFile to check
* @rp: copy of the current restart page
*
* Analyze the $LogFile journal and return TRUE if it indicates the volume was
* shutdown cleanly and FALSE if not.
*
* At present we only look at the two restart pages and ignore the log record
* pages. This is a little bit crude in that there will be a very small number
* of cases where we think that a volume is dirty when in fact it is clean.
* This should only affect volumes that have not been shutdown cleanly but did
* not have any pending, non-check-pointed i/o, i.e. they were completely idle
* at least for the five seconds preceding the unclean shutdown.
*
* This function assumes that the $LogFile journal has already been consistency
* checked by a call to ntfs_check_logfile() and in particular if the $LogFile
* is empty this function requires that NVolLogFileEmpty() is true otherwise an
* empty volume will be reported as dirty.
*/
BOOL ntfs_is_logfile_clean(ntfs_attr *log_na, RESTART_PAGE_HEADER *rp)
{
RESTART_AREA *ra;
ntfs_log_trace("Entering.\n");
/* An empty $LogFile must have been clean before it got emptied. */
if (NVolLogFileEmpty(log_na->ni->vol)) {
ntfs_log_trace("$LogFile is empty\n");
return TRUE;
}
if (!rp) {
ntfs_log_error("Restart page header is NULL\n");
return FALSE;
}
if (!ntfs_is_rstr_record(rp->magic) &&
!ntfs_is_chkd_record(rp->magic)) {
ntfs_log_error("Restart page buffer is invalid\n");
return FALSE;
}
ra = (RESTART_AREA*)((u8*)rp + le16_to_cpu(rp->restart_area_offset));
/*
* If the $LogFile has active clients, i.e. it is open, and we do not
* have the RESTART_VOLUME_IS_CLEAN bit set in the restart area flags,
* we assume there was an unclean shutdown.
*/
if (ra->client_in_use_list != LOGFILE_NO_CLIENT &&
!(ra->flags & RESTART_VOLUME_IS_CLEAN)) {
ntfs_log_error("The disk contains an unclean file system (%d, "
"%d).\n", le16_to_cpu(ra->client_in_use_list),
le16_to_cpu(ra->flags));
return FALSE;
}
/* $LogFile indicates a clean shutdown. */
ntfs_log_trace("$LogFile indicates a clean shutdown\n");
return TRUE;
}
The “ntfs_is_logfile_clean” function is called from the “ntfs_volume_check_logfile” function. The latter function is called from the “ntfs_device_mount” function. Here is a piece of code from the “ntfs_device_mount” function:
/*
* Check for dirty logfile and hibernated Windows.
* We care only about read-write mounts.
*/
if (!(flags & (NTFS_MNT_RDONLY | NTFS_MNT_FORENSIC))) {
if (!(flags & NTFS_MNT_IGNORE_HIBERFILE) &&
ntfs_volume_check_hiberfile(vol, 1) < 0) {
if (flags & NTFS_MNT_MAY_RDONLY)
need_fallback_ro = TRUE;
else
goto error_exit;
}
if (ntfs_volume_check_logfile(vol) < 0) {
/* Always reject cached metadata for now */
if (!(flags & NTFS_MNT_RECOVER) || (errno == EPERM)) {
if (flags & NTFS_MNT_MAY_RDONLY)
need_fallback_ro = TRUE;
else
goto error_exit;
} else {
ntfs_log_info("The file system wasn't safely "
"closed on Windows. Fixing.\n");
if (ntfs_logfile_reset(vol))
goto error_exit;
}
}
/* make $TXF_DATA resident if present on the root directory */
if (!(flags & NTFS_MNT_RDONLY) && !need_fallback_ro) {
if (fix_txf_data(vol))
goto error_exit;
}
}
We can see that another strange message (“The file system wasn’t safely closed on Windows. Fixing.“) is in this piece of code. After printing this message, the “ntfs_logfile_reset” function is called, which calls the “ntfs_empty_logfile” function. The “ntfs_empty_logfile” function writes the 0xFF pattern to the $LogFile.
Let’s go back to the “ntfs_device_mount” function: the “$LogFile reset” branch of code is inside the “(!(flags & (NTFS_MNT_RDONLY | NTFS_MNT_FORENSIC)))” condition. So, this branch of code isn’t executed during the read-only mount. We remember that the initramfs script probes a file system by mounting it using the “ro,noatime” options. Thus, there is no reason for the $LogFile to become wiped!
Again: what happened?
I found that there is a bug in the BusyBox toolset, which is used by initramfs scripts in live distributions based on Ubuntu. The bug is in the implementation of the mount command: when the “mount” call fails to mount a file system, an external helper program is launched to mount this file system; the read-only option isn’t passed to the helper, so the file system is mounted in the read-write mode by the helper (this file system will be unmounted later because it doesn’t contain a root file system image).
And the conclusion is: booting a live forensic distribution like PALADIN 6.09 results in an NTFS file system on a suspect drive being mounted in the read-write mode for a short period of time! If the file system is dirty (not properly unmounted), then the $LogFile is wiped. However, this is not the case when a Windows operating system is hibernated.
This issue was observed by other researchers, but they didn’t investigate the root cause. Here is a list of reports:
- Test Results for Digital Data Acquisition Tool: ASR Data SMART version 2010-11-03 (NIST). The report contains the following statement: “The source drive, 01-IDE, contained an NTFS and several other file systems. In each case 88 sectors belonging to the NTFS file system journal were changed.” (page 8). It should be noted that there is no similar statement in reports for other live forensic distributions affected by the same issue (I suppose that NIST encountered the issue accidentally).
- Testing the Forensic Soundness of Forensic Examination Environments on Bootable Media (Ahmed Fathy Abdel Latif Mohamed, Andrew Marrington, Farkhund Iqbal and Ibrahim Baggil). The authors didn’t make any claims regarding the nature of the modifications they observed in the Helix3 Pro 2009R3 case, but I think that the only explanation for their findings is this NTFS issue.
Also, this issue resulted in important evidence missing in one of my cases (when someone was playing with a suspect drive before sending it to a lab).
Addendum (2018-07-25):
@JPoForenso suggested to use the “ro,noload” options when mounting a dirty Ext4 file system (to disable a journal). There is a known issue with this solution: when an Ext4 file system contains orphan inodes (i.e., files unlinked while opened), these inodes are cleaned even when the “ro,noload” options were specified (and there is no explicit mount option to disable orphan inodes deletion); during this operation, the following kernel messages can be observed:
EXT4-fs (loop0): orphan cleanup on readonly fs EXT4-fs (loop0): 1 orphan inode deleted EXT4-fs (loop0): mounted filesystem without journal. Opts: noload

One thought on “A live forensic distribution writing to a suspect drive”