Although NTFS has been designed with case-sensitivity in mind, it’s used mostly in the case-insensitive environment. One can natively store, within the same directory, two or more files with their names differing only in case, but Windows-based tools won’t deal with them correctly. To provide true case-sensitivity, Microsoft implemented an additional layer, per-directory case-sensitivity, as described here, here, and here.
But there are several issues with usual, case-insensitive, operations…
To implement a case-insensitive file system, one needs to compare two file names in a case-insensitive way. There are three ways to achieve this:
- uppercase two names and compare them;
- lowercase two names and compare them;
- case-fold two names and compare them.
Case-folding is described here:
Case folding in Unicode is primarily based on the lowercase mapping, but includes additional changes to the source text to help make it language-insensitive and consistent. As a result, case-folded text should be used solely for internal processing and generally should not be stored or displayed to the end user.
When implementing any of the above, the following problem arises: Unicode is changing all the time. You can never be sure that a given string is going to be uppercased, lowercased, or case-folded in the same way five years later.
For example, the Unicode standard version 13 (2020) introduced 169 new case-folding entries compared to the Unicode standard version 8 (2015), this includes nine case-folding entries for Cyrillic characters, twelve entries for Latin characters.
So, case-mapping data must be kept stable to preserve the outcome of case-insensitive lookups.
Imagine two file names mapped into non-identical uppercased/lowercased/case-folded forms and a system update leading to these file names being mapped into identical uppercased/lowercased/case-folded forms! A file system driver will unexpectedly find two existing files sharing the same name. So, the case-mapping data should be defined during the format operation and stay the same.
Two solutions to this problem are known:
- write the Unicode version used to the file system header;
- store the case-mapping data within the file system.
Obviously, stabilizing case-mapping data by specifying its version in the file system header isn’t forward compatible (new case-mapping data requires an update).
Here are some real-world examples of case-insensitive file system implementations:
| File system | Case mapping used for comparisons | Case mapping is preserved by… |
| Ext4 <1> | Case-fold | Writing the Unicode version used to the superblock |
| NTFS | Uppercase | Storing the uppercase table within the volume |
| ExFAT | Uppercase | Storing the uppercase table within the volume |
<1> Case-insensitivity is an optional feature.
Stable case-mapping data also brings another problem: a file system driver can perform case-insensitive comparisons with different results compared to applications and other drivers.
This could happen if a file system driver and an application (or another driver) use different case-mapping data. In such a case, comparing the same string case-insensitively can lead to different results!
Now, let’s take a look at uppercase functions commonly used in Windows.
The RtlUpcaseUnicodeString() and RtlUpcaseUnicodeChar() functions use the system-wide uppercase table (together with faster code for a-z characters). This table is loaded by the Windows loader and then passed to the kernel.
The NTFS driver mainly uses per-volume uppercase tables (and even characters from the a-z range are passed through this table).
Internally, a Windows operating system deals with so-called wide characters. These are two-byte characters corresponding to the UTF-16LE encoding with no support for surrogate pairs (if present, they are treated literally, as two two-byte characters, no attempt is made to merge surrogate pairs into proper code points). Wide strings (strings composed of wide characters) can be displayed by a usermode application with surrogate pairs merged into proper code points. However, for uppercase purposes, each surrogate pair is just a sequence of two wide characters.
Some programming languages (like Python) provide uppercase functions not based on Windows ones.
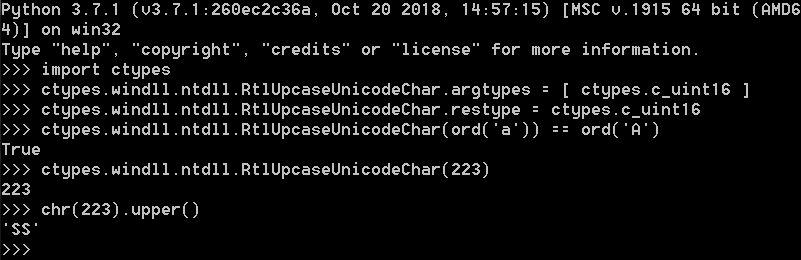
In Windows 10 “21H1”, the system-wide uppercase table is the same as the uppercase table written to NTFS volumes during the format. This uppercase table is out-of-date — within the 0-0xFFFF range, 212 characters have out-of-date uppercase forms.
In Windows 10 (“21H1” and earlier versions), 8.1, 8 & 7, the same uppercase table is written to NTFS volumes during the format operation. However, Windows Vista uses a different (older) uppercase table.
So, attaching an NTFS volume formatted under Windows Vista to a computer running Windows 10 results in different case-mapping data used by the operating system and by the file system driver. Interestingly, you can upgrade from Windows Vista to Windows 10 by launching the “custom” installation from a bootable drive, even without reformatting the target drive (so an existing uppercase table within the system partition will be “migrated” to Windows 10).
Let’s compare two installations of Windows 10: a clean one and another one made on top of Windows Vista.
In each installation, let’s try to create two directories with the following names (under the same parent directory): “testɐ” and “testⱯ”.
Note that the “Ɐ” character is the uppercase form for the “ɐ” character.
In the uppercase table native to Windows 10 “21H1”, the statement above is true.
In the uppercase table native to Windows Vista (which was “migrated” to the system volume of Windows 10 “21H1”), the statement above is false (the uppercase form for the “ɐ” character is the same character).
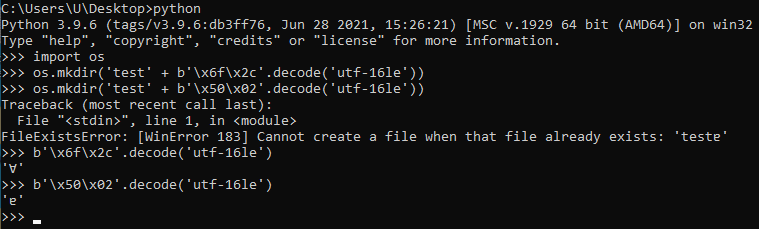
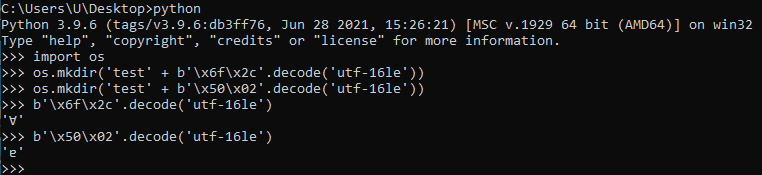
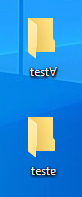
Also, an NTFS volume can contain a specially crafted uppercase table. For example, an attacker can remap the ASCII range in a weaponized disk image, similar to this:
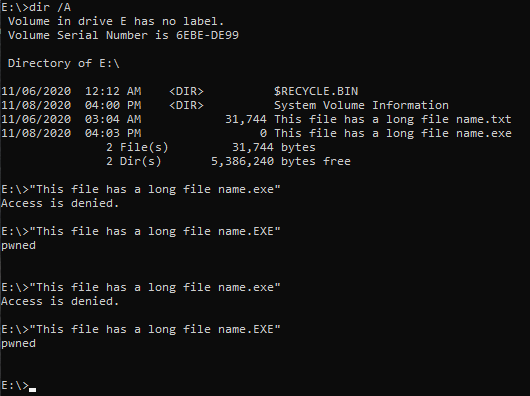
And the conclusion is:
When working with a case-insensitive file system, don’t change the case of a file name returned by the file system driver. There is no guarantee that the converted name points to the same file.
Does this affect DFIR tools?
Unfortunately, yes. Tools that perform case-insensitive lookups in $I30 records or deduplication of file path lists can be affected.
For example, the RawCopy tool performs case-insensitive lookups in $I30 records when resolving a path to a file to be copied, but the uppercase table stored on a volume isn’t used for that. In the “ɐ”/”Ɐ” scenario similar to the described above, when two files in one directory have almost identical names containing the “ɐ”/”Ɐ” character, the tool won’t see both files at once (only one file will be copied for both input file names).

Great post !
Fyi, the $UpCase:$Info resident content at offset 0x08 has the 64-bit CRC of the $UpCase file. It is used to check is the $UpCase character mapping table is current or obsolete. The current CRC64: 0xDADC7E776B1B690C been the same since Windows 8.1 (Windows builds 9600, 14393, 17134, 19041, 21322, 21996), indicating that the $UpCase mapping table has remained the same.
LikeLike
Also: https://twitter.com/errno_fail/status/1258900141479809025
LikeLike